I recently had the opportunity to start learning reverse engineering, to try to puzzle out how some existing software works. It was less intimidating than I expected, and this post covers some of the background knowledge I had to learn and how I used Binary Ninja to interpret the disassembled code. This software was written in C++ and compiled for x64 Windows, and included tens of DLLs (Windows libraries).
Level 1: Binary Noob
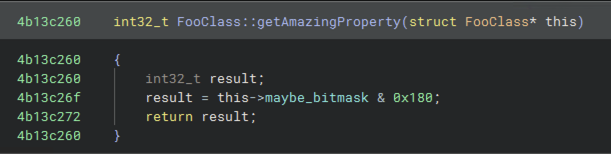
I started with a simple task: there was a number we were pretty sure was a bitmask, and I needed to figure out what the bits meant and which were the ones we cared about. This stage involved learning what happens when you load a DLL into Binary Ninja, how to find functionality of interest, how to read Binary Ninja’s intermediate languages, and how to annotate the disassembly by constructing type definitions.
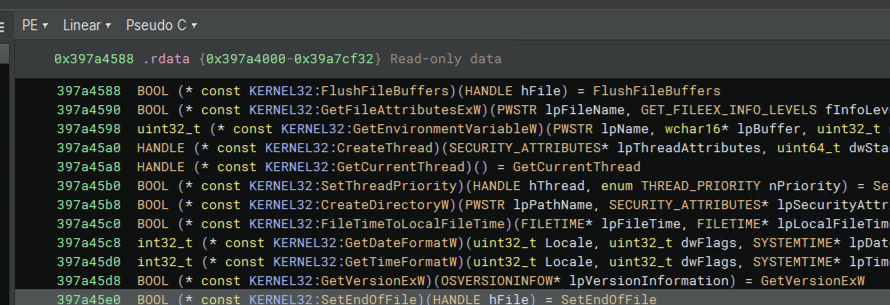
I knew roughly what functionality I was looking for, based on the name of this field and related concepts in the API, so I was able to find a related DLL using ripgrep to search for strings of interest within the binaries. After opening it in Binary Ninja, it was easy to tell if a function of interest was imported from another DLL via the cross-references or Triage Summary. For example, here’s what some imports from kernel32.dll looked like:
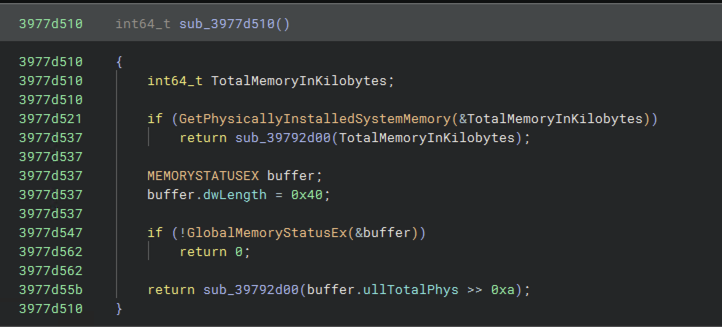
It took me a bit of time to learn how to interpret Binary Ninja’s various intermediate languages. When you load a DLL into Binary Ninja, it extracts symbol names from the binary to name as many functions, constants, etc as possible. There’s a bit of documentation on reading its intermediate language, but I still saw a lot of things I didn’t understand. I spent most of my time looking at the highest level, “Pseudo C” representation, where Binary Ninja attempts to reconstruct as much control flow as possible from the disassembly, and at this level, some functions were actually very readable:
Sometimes, though, the symbols were a complete mess. What does the function “?CompareNoCase@?$CStringT@DV?$StrTraitMFC_DLL@DV?$ChTraitsCRT@D@ATL@@@@@ATL@@QEBAHPEBD@Z” do? It turns out the C++ compiler distinguishes symbols for overloaded functions by “mangling” them; I used https://demangler.com/ to de-mangle them. This one is public: int __cdecl ATL::CStringT<char,class StrTraitMFC_DLL<char,class ATL::ChTraitsCRT<char> > >::CompareNoCase(char const * __ptr64)const __ptr64, aka CStringT::CompareNoCase.
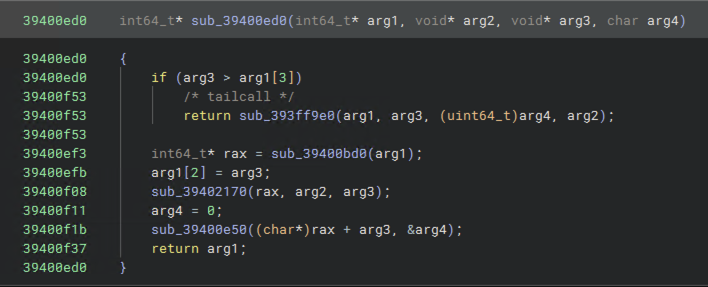
Other functions were completely uninterpretable without more investigation:
Most of my time was spent constructing type definitions to make functions like these easier to understand.
Constructing type definitions
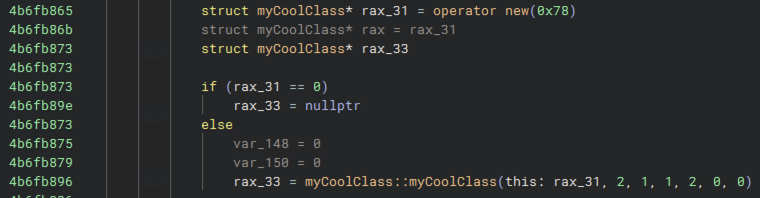
After finding a class of interest, the next step was almost always to start figuring out its layout in memory. The easiest way to figure out its size was typically to search for callsites of its constructor. Here, myCoolClass is 0x78 bytes:
The next thing I looked for was usually getters and setters, since they often made it easy to figure out the purpose of data stored at a given offset. This is how I figured out most of the bitmask fields!
The software I was investigating made heavy use of inherited classes, so I also spent a lot of time setting up vtable definitions for the types I defined, in order to correctly propagate cross-references to functions inherited from their superclasses. Basically, in C++, a struct’s first 8 bytes are typically a pointer to the vtable containing all the functions it inherits from its parent class (for single inheritance). Binary Ninja has great documentation on how vtables are laid out in memory, how to create type definitions for them, and how to handle multiple inheritance. After a few read-throughs of these docs I was pretty comfortable setting up vtables for the types I created!
Level 2: Binary Navigator
I spent most of my time in Binary Ninja’s “Pseudo C” view, but sometimes I needed to drop down to a lower level of abstraction.
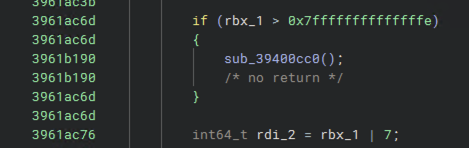
Sometimes, Binary Ninja made mistakes reconstructing the control flow from the disassembly, and the best way to figure out what was going on was to drop down to the disassembly representation. For example, I was really surprised to see lines of code in the Pseudo-C view “out of order” according to their memory addresses:
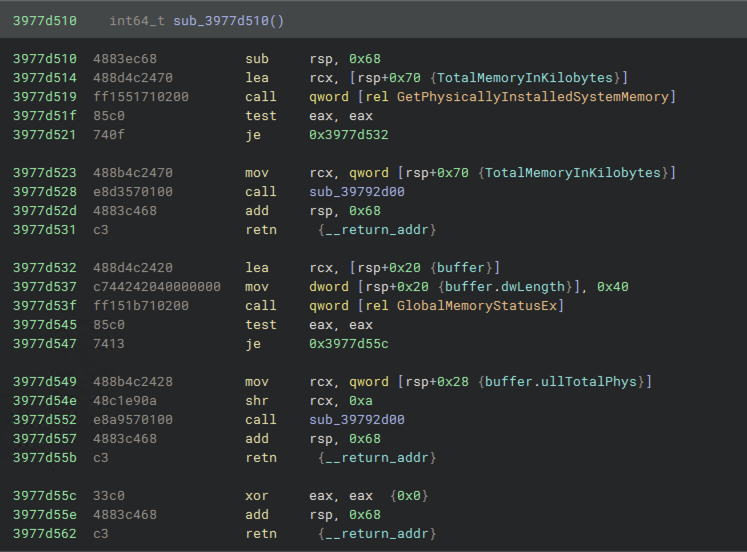
When I saw things like this at the Pseudo-C level that I didn’t understand, taking a look at the actual disassembly often resolved my confusion. As an example of what information is presented in the disassembly view, here’s what the memory-related function from earlier looks like at that level:
At this point it was obviously pretty helpful to have a basic understanding of x64 assembly.
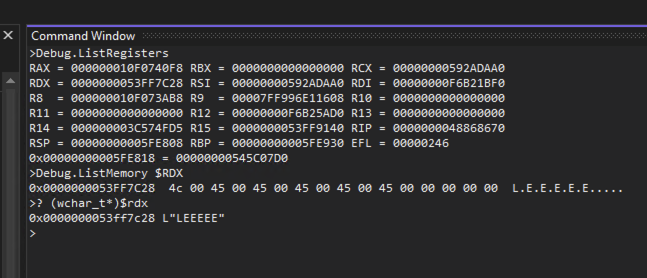
I also sometimes used Visual Studio or WinDbg to debug some of the DLLs, by inserting breakpoints either on Windows syscalls, or on functions I found in Binary Ninja. Binary Ninja has a debugger, but it can only be used on one DLL at a time; Visual Studio’s debugger is better for tracing a call stack across multiple DLLs. Since Visual Studio isn’t a disassembler, it can’t reconstruct function signatures from the DLLs, so I needed to use the x64 calling convention to know which registers held which arguments for the function I was debugging. In this example, the function’s second argument was a Unicode string, passed via the RDX register:
The calling convention also helped me quickly identify which arguments were integers and which were floats, and to understand why some registers appeared to be frequently reused within a function definition while others did not (the reused registers were volatile, meaning they did not have to be restored when the function returned).
Level 3: Binary Ninja
At this point, I’ve basically uncovered the tip of the iceberg and would hardly call myself a Binary Ninja. The good news is that I have a bunch of ideas for improving my skills and workflow.
The first is just to do a bunch of experimentation with writing small C++ programs and looking at the disassembly. I was originally going to do this on my computer, but I discovered https://godbolt.org/, which lets you see the output with different compilers!
The second is to get more comfortable with the tools I’m already using and maybe add a few more where needed. Specifically, the Visual Studio debugger has been helpful, but it still feels very friction-y. In addition, a few of the DLLs I’ve encountered have resources built in, which I have not explored at all. For example, I’d need to inspect the DLL’s resources to find out what string literal gets loaded into this variable:
There are a few tools I could use for resource extraction from DLLs (Visual Studio, Resource Hacker, PE Explorer, etc), but I haven’t had the time to figure this out yet.
The last main way I think I could improve at reverse engineering is to try to automate repetitive or annoying parts of my workflow. Here are a few candidates that come to mind:
Binary Ninja auto-generates some “system types”, including types for vtables. Unfortunately, though, they often can’t be saved as-is because they have errors like duplicate function names or references to types that don’t exist yet. For example:
I have been fixing these by copying the vtable definition into an editor, adding numerical suffixes to function names, and replacing instances of unknownClass* arg1 with struct unknownClass* arg1. This is pretty tedious and often not worth it for large vtables. I vibecoded a small python script to help with de-duping function names; I’d like to improve the script and ideally find a way to “fix up” these vtable definitions without having to leave Binary Ninja at all.
I sometimes used Visual Studio for debugging, when I wanted to see the whole call stack (across multiple DLLs) at a breakpoint, but Visual Studio doesn’t have access to symbols in the files I was debugging. It would be great to write something to combine the call stack information from Visual Studio with the symbol information from Binary Ninja. This seems pretty possible with the Binary Ninja API.
I’ve been using a type archive to share type definitions between each DLL’s database. This works really well for the most part. However, if I accidentally end up with changes to a type in both the archive and the database, there’s no easy way to “diff” them, other than copying both definitions into an editor/diff checker and comparing. This solves a smaller problem than the other two ideas, but I could see it being useful to other people too, maybe as a plugin.
Organizational strategies
Compared to my normal software engineering tasks, reverse engineering not only needed more technical background knowledge; it also was more challenging and draining in less technical ways. Here are a few of my coping strategies!
Taking notes
Working at a lower level of abstraction is really hard, because you need to digest a much larger volume of code and keep track of many more things in your head at once. It also makes context switching very expensive, and takes a while to get into a flow state. I adapted some note-taking strategies I use for debugging to help prevent me from getting overwhelmed while reverse engineering.
When I’m debugging, I try to:
Write down what I observed, including context like logs, screenshots, etc, and as many details as possible about what triggered the behavior, even if it’s not reproducible
Write down why my observations don’t match what I expected. This is the easiest way to discover where my mental model doesn’t match reality, and it lets me rubber duck without bugging other people!
Brainstorm as many ideas as I can about what might be happening. It’s usually really tempting to start investigating the first idea you come up with, but sometimes other ideas are more promising or easier to experiment with.
Come up with a few small experiments that can give me enough evidence to accept or reject one of my guesses.
It turns out this strategy also works reasonably well for me for reverse engineering. In addition to tags, bookmarks, and comments in Binary Ninja, I use a notes doc to keep track of observations and ideas. This helps keep me from going too far down rabbit holes without a clear objective in mind. Brainstorming experiments is also a good reminder that there may be easier ways to answer a given question than to keep digging into disassembly; for example, I could often find clues in Microsoft’s documentation for open specifications and MFC.
For both debugging and reverse engineering, I find it helpful to be willing to try a number of different strategies without knowing which one is going to work out. Plus, taking breaks helps!
Versioning and collaboration
So far I haven’t developed a good strategy for “versioning” the type definitions, variable names, and other changes I make. I’m not sure if there’s any way to “go back in time” so I take good notes and try to avoid making mistakes (this results in a lot of variable names like maybe_foo or bar_unknown_size).
I also would love to figure out a good strategy for sharing Binary Ninja database files with other engineers. There is a way to import/export type definitions from database files, but I’m not sure if this would work well when multiple people are working in the same Binary Ninja database. So far, I’ve been investigating different DLLs/functionality than the other engineer I’ve been working with,
so we haven’t had to solve this problem yet, but it seems hard to get your work into a state where others could easily pick up where you left off. Maybe we could check our own type archives into git LFS and attach both type archives to the databases we’re working with?
It might just be because I work on version control software, but since it takes so much time and energy to annotate disassembly, it would be awesome to see more version control related features in Binary Ninja. It’s also possible that there’s just no good way to collaborate closely on this work.
That’s it!
Capture-the-flags and problem sets have their place, but I almost always find solving a real problem to be much more engaging! I am really grateful to have the chance to learn things like this in service of a real problem, and to have mentors who are willing to teach me. Hopefully I’ll continue to improve on my journey to becoming a Binary Ninja!